Introduction
A mathematical model that maps points in a three-dimensional space to a two-dimensional space.
Okay, picture this: You are standing in front of the tallest building on the planet, Burj Khalifa. You’re fascinated by what you are looking at, and you click a picture with your camera. Now, the three-dimensional world is captured into a two-dimensional flat plane.
Note: When mapping to a lower dimension, we lose some data. Here, we sacrifice the depth.
Importance
Consider an autonomous vehicle with stereo cameras (two cameras set side-by-side replicating the human eye). We can use 2D images from stereo vision to estimate the depth when the image is formed.
Are you not intrigued yet? Take the case of Google Maps. We have some structures in 3D instead of 2D satellite images. How did they achieve this? 3D reconstruction can accomplish this. By mapping points from 2D images to 3D space, Google can reconstruct the geometry and appearance of structures in three dimensions.
Derivation
To derive the pixel coordinates from the World coordinate system. We use the following method:

Here, the mapping from 3D to 2D happens at the third step between the Camera Coordinate and the Film coordinate. Now, what do these coordinates mean?
World Coordinate
It simply refers to the 3D space of the World we live in or the 3D space, which is a matter of interest for our observation. The 3D positions of objects in the scene relative to a global reference frame. These coordinates are typically defined in a coordinate system independent of the camera’s position and orientation.
Camera Coordinate
It represents the positions of objects relative to the camera itself. This coordinate system is centered at the camera’s optical center and aligned with its orientation. It accounts for camera intrinsics like focal length and principal point.
Film Coordinate
This system obtains a mapping of 2D space by projecting the 3D scene onto a 2D film plane. It accounts for the camera lens distortion, which affects the 3D to 2D mapping.
Pixel Coordinate
Now, with the 2D film plane, it is projected onto a grid of pixels to make an image.
Derivation (Contd.)
Why do we need all these separate coordinate systems instead of mapping directly to pixel coordinates? We need a reference when we map from one function to another in an n-dimensional space. Mapping directly to pixel coordinates without considering intermediate coordinate systems can lead to inaccuracies and inefficiencies in the projection process. Hence, when mapping from the World to a Pixel, we should first consider the camera coordinates, then the film coordinates, and finally, derive the pixel coordinate. This ensures the accuracy of the transformation.
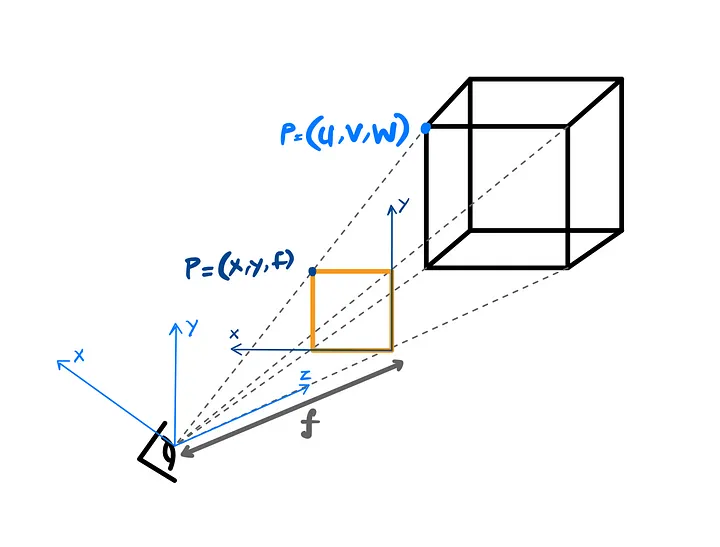
How do we express them mathematically? The simple trick is to take XYZ, and xy coordinates to form two triangles and use a similar triangle rule:
Hooray, we are done! Or are we? Now, how do we represent it in its matrix form? We introduce homogeneous coordinates.
In homogeneous coordinates, we represent a 2D point (x, y) as a 3D point (x’, y’, z’). Mathematically, it can be expressed as:
In the camera coordinate system, we would get a matrix equation like:
When transforming the world coordinate to a camera coordinate system, we need to find the location and the orientation of the camera reference frame to the known world reference frame.
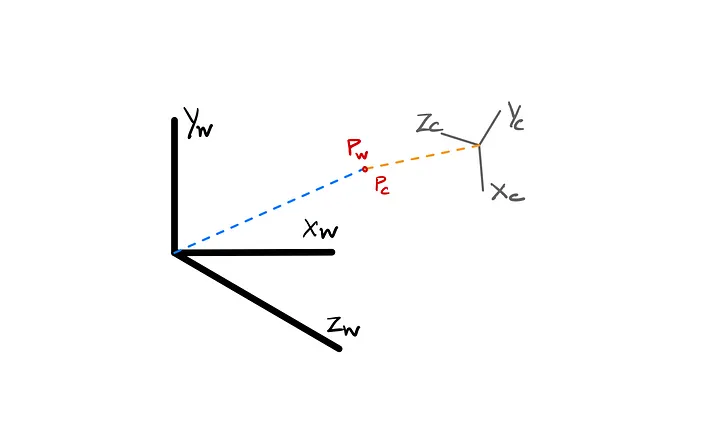
Now, the parameters that define this transformation are:
- A 3x3 translation vector T describing the relative displacement of the origins of the two reference frames.
- A 3x3 rotation matrix R that aligns with the axis of the two frames.
The equation for the transformation is given as:
Ultimately, we have to consider the intrinsic and extrinsic parameters to derive the transformation from the World to Pixel coordinate. The parameters for the transformation are:
where is the interior transformation matrix and is the exterior transformation matrix. Here, (s_x, s_y) is the scaling factor to denote in the pixels, and (o_x, o_y) is the image center point.
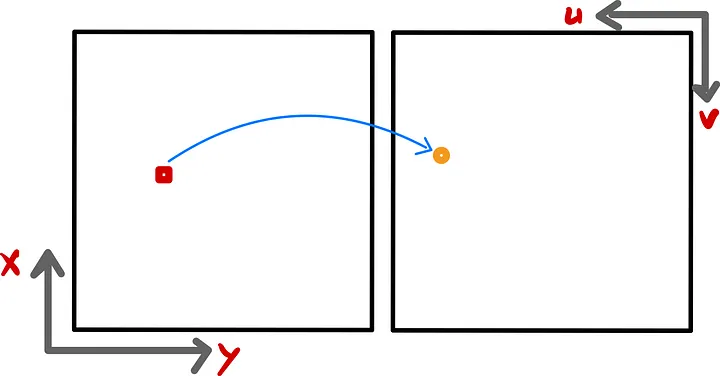
We use an affine transformation from the film coordinate to the pixel coordinate. It preserves parallelism and collinearity, but we lose information about the orientation. Hence, the final equation becomes:

Conclusion
Overall, camera projection is a versatile and indispensable tool in numerous fields, enabling the transformation of 3D spatial information into 2D representations for visualization, analysis, and interaction.
In essence, we need camera projections to perform:
- Computer graphics rendering
- 3D Scene Reconstruction
- Virtual reality (VR) and Augmented reality (AR)