Introduction
EVOL-RL is a label-free online-RL technique (can also be used in place of labeled dataset), which improves TTRL by introducing three main blocks in its method. This is built on top of GRPO and showcases how LLMs can evolve without having to pay the trade-off between exploitation-exploration in RL.
Before jumping in, it is suggested that the readers read the TTRL paper available as a pre-print on ArXiv, or my previous blog post on TTRL. If you are in a hurry, this is all you need to know:
TTRL is a label-free online-RL technique, which uses majority-voting system as its reward function. It is built on top of existing RL policy techniques in optimizing LLMs.
While it may sound good on paper, it isn’t - which was spotted by the researchers at Tencent AI labs in collaboration with University of Notre Dame and University of Virginia. They discovered that while TTRL performed well on pass@1 (click here to learn about it), it was poor when tested for pass@n tests.
The researchers claimed it was because of its own mechanism, as the entropy collapsed either soon or over-time as the reward signal diminished over-time. Since TTRL prioritizes answers that are present in majority, it learns from it, and when normalized using z-normalization in GRPO, it won’t learn from the new signal as the probability mass stays at the mean of the reward distribution. Hence, this diminishes the entropy, and hence, exploitation happens after a few training steps. To tackle this issue, the researchers proposed EVOL-RL.
How does it work?
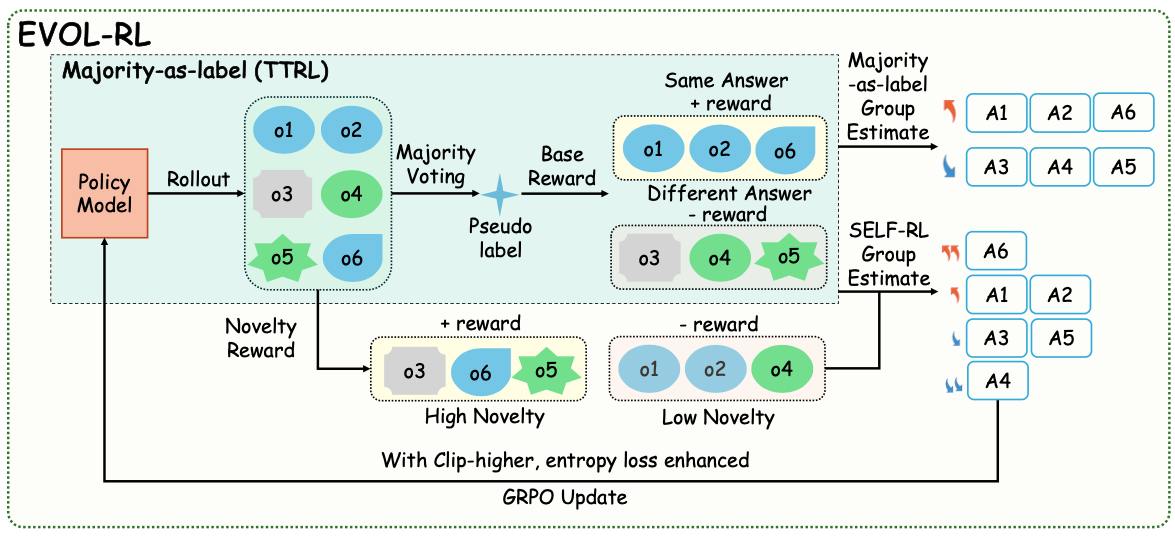
EVOL-RL has 3 important blocks that work hand-in-hand. They are:
- Novelty-reward function: Picks the best candidate out of the sampled response.
- Entropy regularization: Aids in exploring the best possible response in a rollout.
- Asymmetrical clipping: Learns from the best candidate with highest diversity from a response with high-reward signal.
Novelty-reward function introduces a new technique to the majority-voting system. Instead of rewarding binary signal, a similarity score index is used locally and globally. What does this mean? As seen previously, with GRPO normalizing our reward signal, there won’t be any difference while updating the parameters though the signals constitute different values as the difference is insignificant. Hence, in EVOL-RL, the reward function prioritizes on local and global diversity in the sampled outputs.
Consider this example, you sample for a question:
“What is 6 x 7?”
And then, the LLM responds with these:
- “The answer is 42”
- “It is 42”
- “42”
- “The answer is 43”
- “It is 43”
Similarities within majority ( answers):
- (1 vs 2) = 0.95
- (1 vs 3) = 0.92
- (2 vs 3) = 0.93
Similarities within minority ( answers):
- (4 vs 5) = 0.96
Cross-group similarities (majority vs minority):
- (1 vs 4) = 0.40
- (1 vs 5) = 0.42
- (2 vs 4) = 0.38
From the mean similarity score for response 1 (within majority):
From the max similarity score , which is the most similar response in the entire batch:
Thus, it gives us a picture of how each response differs semantically and helps in rewarding the majority-voted answer with high reward while appreciating exploration.
Locally, it compares the answer’s distinctiveness where the sample responses are in majority. Globally, it checks with all sampled responses. This gives an image of the semantic difference and captures the fine-grained signal which is important to not lose exploration-exploitation balance in RL.
Mathematically, the score from the mean similarity (local) and maximum similarity (global) is represented as:
Where is your mean similarity, and is the maximum similarity. Now the final reward mapping looks like this:
Hence, this function mapping ensures that - even if a minority response is distinct out of the sampled responses, it doesn’t get rewarded higher than the responses with low-diversity with majority-voted answer (only the penalization is minimized).
Moreover, to make it robust to exploration, an entropy regularization block is added to the token-level embedding to promote diversity in its response(s). In GRPO objective function, an asymmetrical clipping block is added to ensure signals of larger gradients are captured and updated.
where
Hence, the total objective becomes:
Why does it perform well?
With these blocks together, the novelty rewards prevent entropy collapse whilst enforcing correctness pressure, entropy regularization maintains diverse rollouts, and asymmetric clipping preserves full gradient signals from these high-value novel solutions - amplifying the selection. Hence, it keeps evolving without entropy collapse like in TTRL.
Results
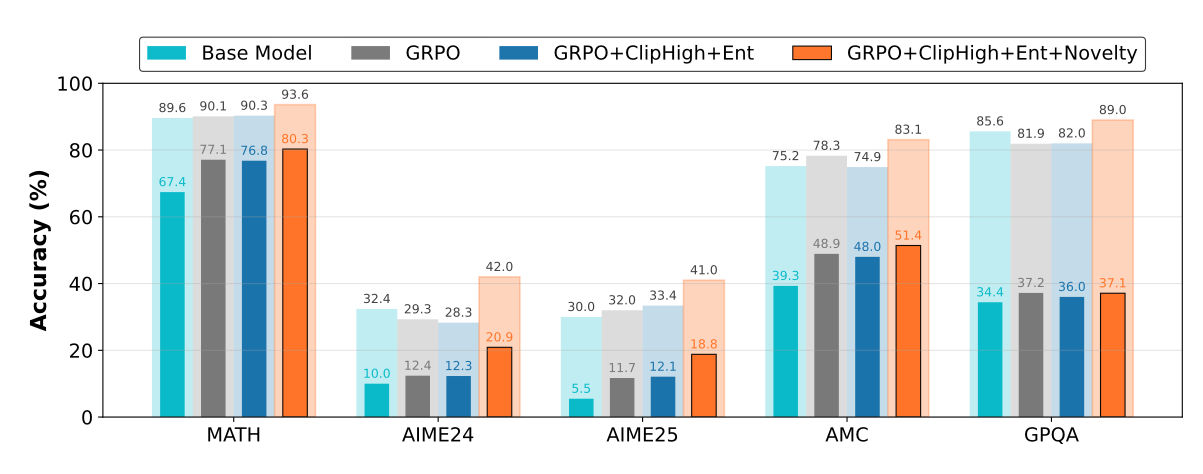
From the ablation chart, it is evident why novelty-reward function is the most important feature of EVOL-RL and key to its success. The main reason contributed is because, with novelty-reward function, the candidates chosen are ensured to have proper distribution in reward signals, and hence - promoting diversity whilst enforcing a directional pressure towards correctness. These blocks work in unison in aiding the model to evolve label-free and thereby not adapting to the dataset by refining its answer (seen in TTRL).
Applications
Use it when:
- Labeled data is scarce: Hardware inspection, code generation in low-quantity dataset, etc.
- Finding new patterns with prior domain knowledge: Scientific discovery in medicine.
Reflection
EVOL-RL is a successor to TTRL, and addresses the main issue of TTRL by adding three key features in its method to ensure exploration-exploitation in RL isn’t one-sided. However, there is still a caveat in Reinforcement Learning - computation cost.
In EVOL-RL, 64 responses are generated per rollout, out of which 32 are sampled for updating the gradients of the model. This technique is adopted from TTRL, and makes no improvement in it. Moreover, if you had thought - why not do adaptive sampling here like me, then here’s why that won’t work! (sorry for sounding harsh.) The problem is - for both of these techniques to work on unlabeled data, less samples cannot be used, as it doesn’t create diversity amongst the sampled responses per rollout. Hence, computational cost is the biggest bottleneck still in this field.
However, is this a true self-evolver? Yes and no. The reason why it is yes is because it encourages exploration whilst training, but no since it needs prior domain knowledge as seen in TTRL - this is because EVOL-RL was built on top of TTRL paradigm with changes made only in its inner-mechanism to boost exploration.
Credits
All content is for educational purposes. Credits to the authors from Tencent AI Lab, University of Notre Dame and University of Virginia for developing EVOL-RL. Read the full paper for technical details.